


Un Puzle de 2 millones de dólares
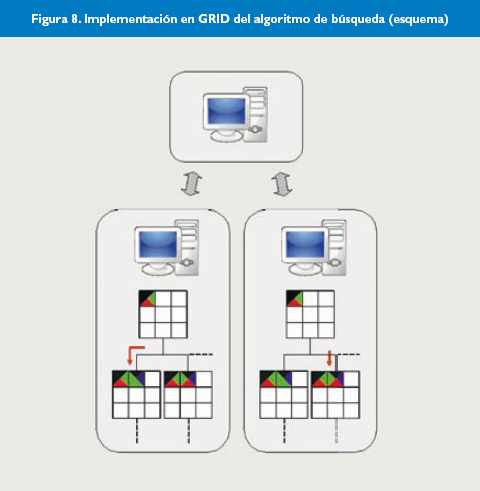
Figura VIII
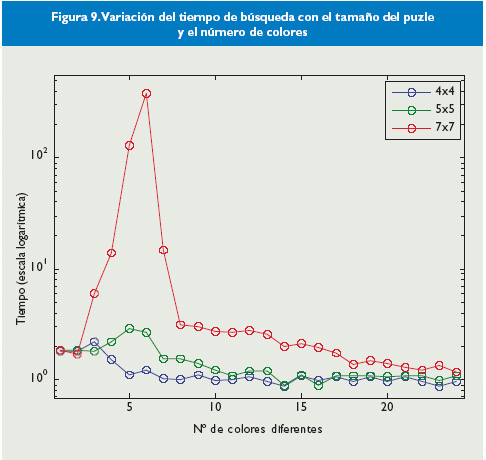
Figura XIX
Implementación utilizando un GRID
Un entorno grid se puede definir como un sistema de cálculo formado por varios equipos interconectados, dispersos geográfi camente y que actúan en paralelo [Foster1998]. Este tipo de sistemas se emplea en aquellos procesos de cálculo donde es posible trocear el problema a gran escala en varios subproblemas y emplear cada uno de los equipos para resolverlos independientemente. Si se coordinan correctamente los equipos, es posible reducir el tiempo total de procesamiento de forma proporcional al número de equipos de los que conste el grid.
Cuando se emplea un grid para buscar la solución del puzle, es necesario adaptar el algoritmo de búsqueda para que permita:
- Avanzar en la búsqueda de la solución de forma independiente en cada ordenador, sin que se produzcan solapes en las posibles soluciones exploradas por cada uno.
- Interrumpir y reanudar la búsqueda, analizando cada vez un número dado de posibles soluciones. De esta forma se pueden asignar flexiblemente estas tareas a los equipos del grid, y parar cuando uno de ellos encuentre la solución.
En la Figura 8 se muestra esquemáticamente cómo se ejecutaría una unidad de trabajo en el grid. El equipo en la parte superior de la figura es el gestor del grid, que envía al resto de equipos (servidores de cálculo) la solución parcial inicial de la que debe partir cada uno. Éstos dan un número de pasos de búsqueda de la solución (colocando piezas o buscando alternativas a las ya colocadas), ensayando la colocación de piezas distintas en cada equipo. Si no encuentran la solución al final del número de soluciones que pueden analizar, devuelven al gestor del grid la situación en la que han quedado. Éste vuelve a asignar esas soluciones parciales devueltas como posiciones iniciales a los ordenadores que hayan quedado libres, y así continúa hasta que algún servidor de cálculo finalmente encuentra la solución.
Resultados experimentales
El enfoque de búsqueda expuesto anteriormente ha sido validado de forma experimental utilizando un grid gestionado por NetSolve bajo Linux [Seymour2005]. Para ello se ha desarrollado en lenguaje C, una herramienta de resolución de este tipo de puzles. Además, para poder disponer de puzles de dificultad variable, se ha completado con un generador automático de puzles aleatorios en el que se puede controlar tanto el tamaño como el número de colores de los mismos. La combinación de estas dos herramientas ha permitido realizar diferentes análisis sobre la complejidad del problema, todos ellos recogidos en [Martín2009].
Por ejemplo, en la Figura 9 se ha representado en escala logarítmica el tiempo necesario para encontrar la solución en un grid formado por varios ordenadores personales de doble núcleo al variar el tamaño del puzle y el número de colores. Este tiempo se ha calculado como promedio de los tiempos obtenidos con varios puzles generados con diferentes distribuciones de colores. Se puede observar que estos resultados son coherentes con los obtenidos teóricamente mediante simulación (Figura 5), así como con los resultados prácticos que aparecen en [Ansotegui2008a] y [Ansotegui2008b].
 |
|
