


Técnicas y datos para la predicción automatizada de tendencias y comportamiento del horno de recocido
Hipótesis planteadas
La automatización del proceso de fabricación y el tratamiento informático de los datos han aumentado en gran medida la cantidad de datos disponibles, haciendo necesario el incremento de la capacidad de los sistemas de almacenamiento.
Para la supervisión del recocido es necesario adquirir la temperatura en los hornos de recocido y la velocidad de línea, así como la remanencia magnética. Para ello se dispone de un sistema de aplicaciones, tablas y otros elementos que permiten adquirir estos datos, generar otros a partir de los adquiridos y visualizar toda esta información. Por tanto, la hipótesis planteada es que hay suficiente información almacenada en los repositorios como para extraer un conocimiento útil, no accesible actualmente de otra forma, sobre la fabricación del acero inoxidable. En concreto, la factoría dispone de un sistema de adquisición de datos que monitoriza los principales procesos, como el funcionamiento de los hornos de recocido, de donde se obtiene un histórico con todas las variables que son de interés.
Los datos necesarios para realizar el estudio y modelo del horno objeto de la tesis se encuentran disponibles en tres orígenes y formatos diferentes:
Tablas de la base de datos de Oracle:
Una aplicación se encarga de comunicarse con un PC-Gateway, que contiene un SCADA, que posee los datos del PLC y que controla el horno de recocido. De éste obtiene, cada cierto intervalo de tiempo, los valores para cada una de las variables de temperatura y velocidad, entre otras. Éstos se almacenan en BD, tanto para su representación en gráficas en tiempo real como en ficheros para la posterior visualización de datos históricos.
Otra aplicación se encarga de calcular la fecha y hora exactas de la entrada en horno de la soldadura que une las bobinas que entran en el horno en un proceso continuo; para ello se basa en la distancia del detector de la soldadura a la boca del horno y en la señal de velocidad y calcula el tiempo que tarda la soldadura en llegar desde el detector a la boca del horno. Además se sabe cuánto mide el horno y cuánto mide la bobina a la que pertenece la soldadura, y también podemos conocer cuándo sale el último metro de la bobina del horno usando la señal de velocidad.
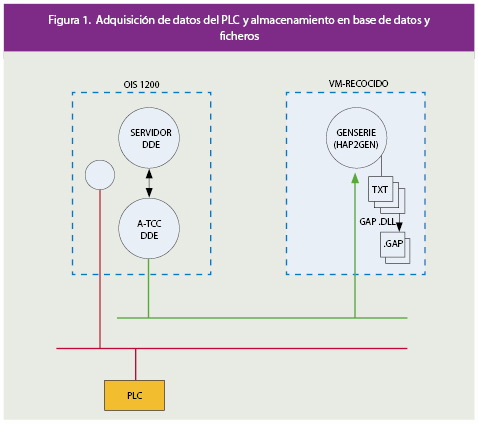
Figura 1.
Ficheros GAP:
GAP.DLL es una librería de enlace dinámico, diseñada para Win32, que comprime y agrupa los ficheros que almacenan las secuencias de valores de las variables de proceso por coladas, con el fin de reducir la gran cantidad de almacenamiento requerido por los mismos.
La aplicación HAP2GEN accede a un servidor en la máquina OIS1200, de donde obtiene los datos vía socket usando el ATCCDDE (instalado en la propia OIS1200).
Los objetivos de la aplicación GENSERIE son la generación de Ficheros GAP, que contienen series de una hora de señales procedentes de un servidor DDE, bien usando DDE o usando sockets con A_TCCDDE como servidor socket en el extremo, donde se encuentra el servidor DDE que nos sirve las señales. GENSERIE también se encarga de trasladar el fichero al Servidor de Datos Continuos, de donde será tomada esta información por uno o varios programas situados en otras máquinas, que la visualizarán y realizarán cálculos con ella.
El objetivo de esta librería es doble: por un lado reducir el tamaño de los ficheros de variables comprimiéndolos y, por otra parte, agrupar a su vez estos ficheros comprimidos, por coladas, en uno sólo. Un fichero GAP se compone de dos secciones: la primera, una especificación del número de versión y revisión de la librería con el que se generó el fichero y la segunda, una serie de 1 a N bloques que contienen los datos comprimidos de los ficheros de variables junto con la información que permite recuperarlos.
El primer campo comprende un único byte que recoge el número de la variable comprimida. Este valor, expresado de forma numérica, será utilizado en el proceso de descompresión para poner nombre a los ficheros de variables descomprimidos. El segundo campo almacena el tamaño original en bytes del fichero de variable, es decir, el tamaño que tendrá el fichero de variable cuando se descomprima. Por último, en el tercer campo se guarda el tamaño en bytes del fichero de variable comprimido, incluido el tamaño de esta cabecera.
La arquitectura general actual de estos dos tipos de datos es la mostrada en el esquema que se muestra a la derecha:
 |
