


Estudio de las relaciones causales: De un marco teórico a una aplicación práctica
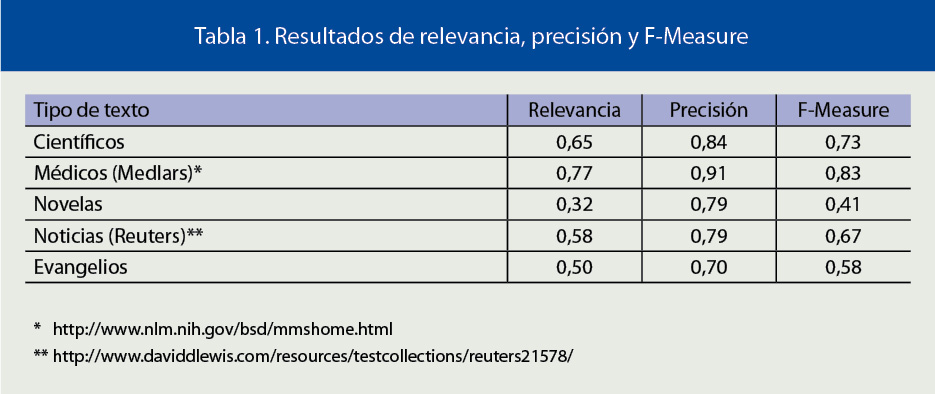
Tabla 1. Resultados de relevancia, precisión y F-Measure.
Dado que el objetivo de este trabajo tiene que ver con el rescate de oraciones causales en textos, será relevante detectar oraciones condicionales que expresen posibles relaciones causales y oraciones típicamente causales en tanto incluyan léxico causal que las caracterice como tales. Para lograr este objetivo, este artículo está dividido en tres bloques. En el primero se presenta un método de extracción y clasificación automático de oraciones condicionales y causales a través de un analizador morfológico. En el segundo bloque se presenta un proceso asociado al anterior, capaz de seleccionar del total de frases extraídas un conjunto relacionado con un concepto en particular, dando como resultado un esquema de representación. En el tercer bloque se describe un experimento en el que se prueba el proceso completo.
Detección condicional y causal en documentos de texto
En [6] se describe un proceso para detectar y clasificar oraciones condicionales en documentos de texto. Estas sentencias se extraen de acuerdo a 20 patrones predefinidos [7] que abarcan los casos más comunes de condicionales en el idioma inglés. Para ello se utilizó el analizador morfológico de libre distribución Flex junto con el lenguaje de programación C, dando lugar a un proceso capaz de seleccionar oraciones de un texto que encajen dentro de unos patrones.
En un principio se analizaron las formas en inglés pertenecientes al condicional en su modo más típico, ‘if x then y’, así como otras fórmulas equivalentes que pudieran dar lugar a este tipo de oraciones (due to, caused by, provided that, have something to do with).
Para comprobar el nivel de fiabilidad de la aplicación se analizaron manualmente una serie de documentos pertenecientes a diferentes ámbitos (50 páginas por categoría), y se calcularon las medidas de relevancia y precisión (en inglés: recall, precision), como se puede apreciar en la tabla 1. La relevancia R es el número de oraciones causales correctamente clasificadas por el sistema dividido por el número de oraciones causales clasificadas manualmente. La precisión P es el número de oraciones causales correctamente clasificadas por el proceso dividido por el total de sentencias devueltas. La medida F (F-Measure) determina la relación entre la relevancia y precisión, viene dada por la fórmula F=(2*P*R)/(P+R), y sirve para controlar la importancia relativa de uno u otro parámetro.
Los resultados indican que los textos científicos y médicos tienen unos mejores resultados en relevancia y precisión que el resto de dominios tratados, por lo que los experimentos a partir de este punto se efectuaron dentro del ámbito médico.
Esquematización automática del grafo causal
Existen varios estudios sobre el análisis de la causalidad en documentos de texto. Algunos están enfocados a la extracción de sentencias causales, como el propuesto por R. Girju [8], y otros en la causalidad y los pronombres interrogativos, como el de Black y Paice [9]. Utilizando estos estudios como referencia se ha creado un algoritmo capaz de lanzar un proceso causal, utilizando un concepto inicial de entrada y el conjunto de sentencias causales y condicionales recuperadas como base de conocimiento. Este concepto de entrada podrá proceder de una pregunta (por ejemplo en un sistema pregunta-respuesta), o ser formulado directamente al proceso.
El siguiente paso consistirá en la localización de todas aquellas oraciones condicionales, previamente seleccionadas, en las que se mencione el concepto solicitado. Se ha creado otra aplicación mediante el analizador morfológico Flex1 que se encarga de generar un fichero de texto plano con las frases seleccionadas.
http://www.gnu.org (última visita: octubre 2010)
http://www.nlm.nih.gov/bsd/mmshome.html
http://www.daviddlewis.com/resources/testcollections/reuters21578/
 |
|
